

As enterprises race to integrate AI into their workflows, I see a growing tension between ambition and practicality. The demand for flexible, cost-effective, and scalable LLM development environments has never been higher. Yet, the high cost of cloud compute, proprietary APIs, and infrastructure often becomes a barrier, especially for startups, R&D teams, and innovation labs.
This is exactly where a zero cost LLM setup changes the equation.
What I find compelling is not just the cost advantage, it’s a shift in how we approach building with AI. Enter the zero-cost LLM dev stack, a practical, open-source-first approach that enables organizations to prototype, test, and even deploy LLM zero cost being locked into expensive infrastructure decisions too early.
Current Affairs on Zero-Cost LLM Stacks
The timing for zero-cost LLM development couldn’t be better. Over the last year, I’ve watched smaller, efficient open-source models have rapidly close the usability gap with larger proprietary systems. Quantized models, instruction-tuned checkpoints, and improved inference runtimes have made even laptops and free-tier notebooks surprisingly capable.
At the same time, the ecosystem has matured. Open inference engines, lightweight vector stores, prompt orchestration frameworks, and evaluation toolkits are now readily available without license fees. The conversation is no longer “Which model is the biggest?” but rather, “Which model is good enough for this task?”
Another important shift I’ve observed is the rise of local-first AI. Privacy concerns, data residency requirements, and cost control are pushing teams to run models locally before even considering the cloud. Free GPU access via community notebooks and efficient CPU-based inference have flattened the entry barrier.
And perhaps most importantly, teams are becoming more skeptical of hype. Flashy demos are losing ground to measurable outcomes such as accuracy, latency, and maintainability. A zero cost LLM setup naturally supports this mindset. It makes experimentation cheap, fast, and disposable, which is exactly how early-stage LLM work should function.
This is where Business Creativity comes into play; the intersection of human insight and intelligent systems. It’s not just about optimizing cost, it’s about fundamentally rethinking how we build. In this context, we don’t just reduce expenses, we Outcreate token-bound experimentation limits, replacing them with a model where iteration is no longer constrained by budget ceilings.
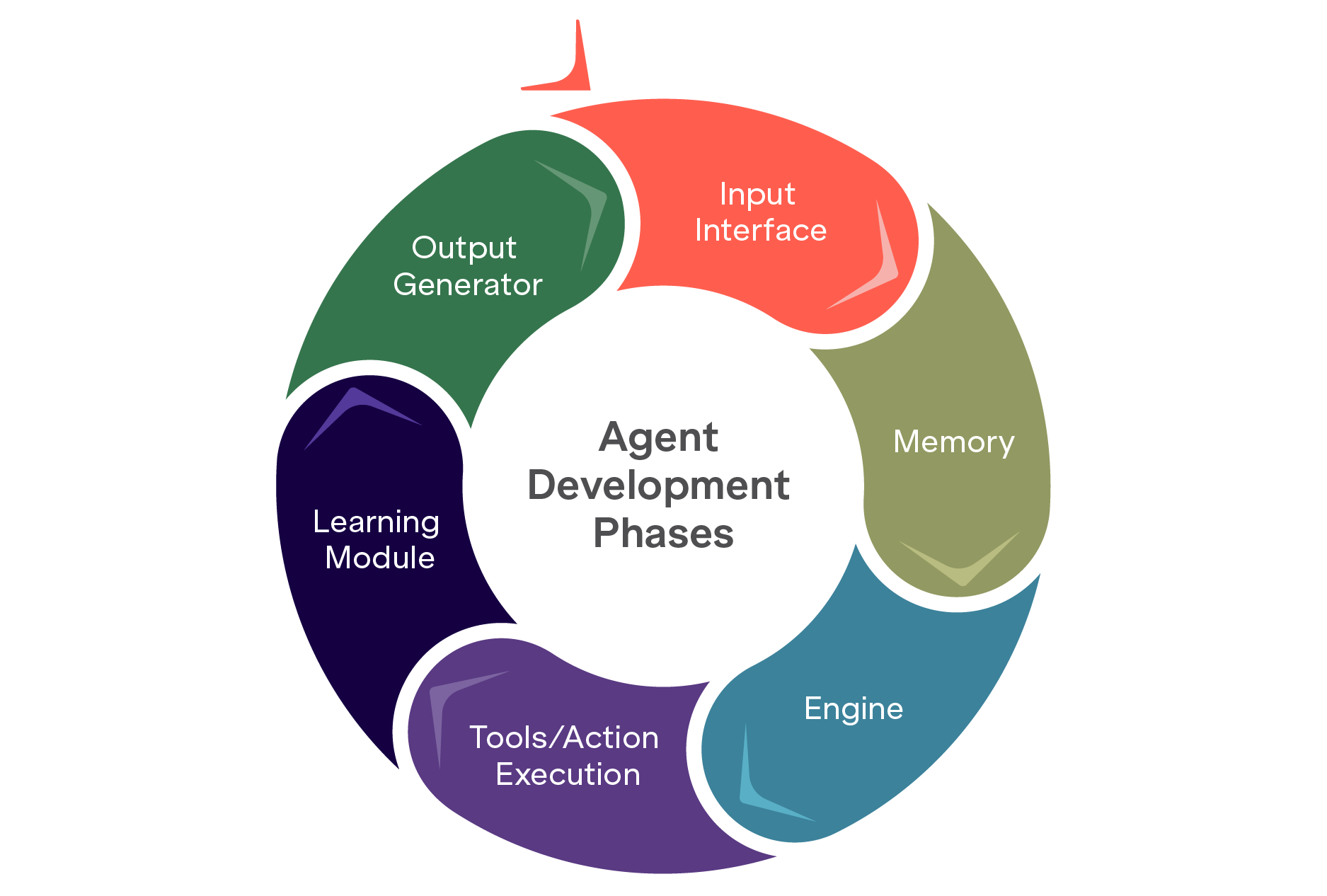
Agent Development Phases
When I look at the development of intelligent agents, particularly those powered by large language models (LLMs), it’s clear that success doesn’t come from tools alone. It comes from structure. The lifecycle typically follows six key stages, each ensuring robustness, adaptability, and alignment with real-world use cases.
What changes with a zero-cost stack is not the phases themselves, but the freedom within them. You can iterate more aggressively, test more scenarios, and fail faster without financial consequences.
Token-Based Cost Challenges in Cloud LLM Agent Development
One of the biggest friction points I consistently see is cost opacity in cloud-based development.
High Token Usage During Development
Frequent prompt iterations and testing lead to multiple API calls. Each call consumes tokens, both in the prompt and the model’s response.
Multi-Turn Interactions Inflate Costs
Agents require multi-step reasoning, memory, and tool usage, significantly increasing the number of tokens per session.
Complex Architectures = More Tokens
Frameworks like Lang-Chain, Auto-Gen, and ReAct generate internal sub-queries. Tool calling, memory integration, and planning logic all add to token load.
Iterative Testing and Debugging
Every variation in prompt design or workflow testing incurs additional cost , especially when simulating real-world tasks.
Scaling Experiments Multiplies Costs
Parallel agents, A/B testing, and simulations can quietly burn through budgets during experimentation.
Trade-Off Between Model Size and Cost
Larger models (e.g., GPT-4) offer better performance but at higher per-token rates. Even though smaller models are cheaper, they may lack the required capabilities.
Cost Becomes a Bottleneck
Without careful planning, token costs can limit iteration speed and innovation. Furthher, budget constraints may force teams to compromise on quality or scope.
This is precisely where local LLMs shift the paradigm. By running models locally using tools like Ollama, teams can deploy LLM zero cost, eliminating per-token API charges and unlocking truly scalable experimentation.
In effect, we begin to Outcreate human-led, cost-constrained development cycles, replacing them with systems that are limited only by creativity and compute, not billing thresholds.
Why Ollama?
Ollama simplifies running LLMs locally with minimal setup. From my experience, it hits the sweet spot between usability and control.
It supports models like LLaMA 2, Mistral, and Gemma, and is ideal for:
- On-premise deployments in data-sensitive environment
- Rapid prototyping without cloud dependencies
- Integration with LangChain for building intelligent apps.
- Running quantized models on local machines or edge devices
What stands out is how it enables privacy-first AI without sacrificing performance, bringing enterprise-grade capcbility into a developer-friendly setup.
How to Setup Ollama as a Docker Container
Minimum system specifications
- Storage: 40 GB
- OS: Linux
- CPU Cores: 8
- RAM: 16 GB
Containerization approach
In this example, I create a Docker container running a Flask web server powered by LLaMA2-7B model. The server accepts POST requests at an endpoint. Upon receiving a request, the server ensures that the necessary requirements are loaded and ready for use. It proceeds to generate a sequence of text based on the provided via request. The generated text is sent back as the server’s response. The server processes incoming requests, and generates responses, essentially functioning as a local inference API.
The architecture is straightforward:
- A Dockerized environment for portability
- A Flask-based interface for interaction
- A locally hosted LLM for inference
This setup allows you to simulate production-like environments without incurring any API costs, making it ideal for testing and internal deployments.
The below figure shows how to create a Docker file to setup a Docker container for Ollama with LLaMA2-7B model.

Now create the python file app/main.py and add the following code to server the request and responses.
Code:

Build the docker image using:

Run the docker image:

Finally, test using the url request to check if the llama is serving the request or not:
Conclusion: Building Smarter, Cheaper, and Freer
If there’s one thing I’ve learned, it’s this: building intelligent agents doesn’t have to come with a hefty price tag.
With the zero-cost LLM dev stack, enterprises, startups, and individual developers alike can unlock the power of LLMs without the burden of cloud costs or vendor lock-in. By leveraging open-source tools, community-driven frameworks, and local deployment solutions like Ollama, teams can experiment, iterate, and innovate at scale, while maintaining full control over their data and infrastructure.
While challenges like hardware limitations, model optimization, and skill gaps remain, the benefits of a zero-cost approach are undeniable: faster prototyping, reduced operational expenses, and a more agile path to AI adoption.
More importantly, this approach is redefining how we work. We’re not just optimizing workflows, we’re creating entirely new ones. We’re enabling new productivity paradigms. And we’re unlocking new roads to value.
That’s the essence of Business Creativity in action. Not incremental improvement, but transformation. Not just doing better, but Outcreating the limits of traditional AI development models.
Because the future of AI development isn’t just powerful. It’s open. It’s local. And increasingly, it’s free.

