Why Unity Catalog is the Backbone of Enterprise AI
Testing

Modern enterprises are undergoing a massive shift. They are not simply experimenting anymore; they are operationalizing AI by building intelligent agents, chat‑based analytics, and automated decision support systems. As this shift accelerates, the role of data teams becomes critical as AI systems can only scale when they are built on trusted, well-governed, and well-cataloged data. This raises a fundamental question for every organization: Is our data foundation truly ready for the AI era?
Often, the AI and machine learning models perform well in pilot but fails in production because the underlying data is inconsistent, poorly governed, or lacks semantic clarity, not because the AI itself is faulty. That is why I see Unity Catalog not as another Databricks feature, but as the strategic backbone for enterprise AI success. Unity Catalog is Databricks’ unified governance layer that centralizes metadata, access control, lineage, metrics, specialized tags, vector indexes, and ensures governance and discoverability right where model operations take place. It provides a single source of truth for governing structured data, unstructured data, and AI artifacts within the Databricks Lakehouse.
Industry Trends Shaping AI, LLM, and Data Management
AI is everywhere; it is becoming more embedded and assistive in how we work and manage daily business operations. From chatbots handling user queries to large language models (LLMs) automating the complete SDLC lifecycle, innovation is happening at a remarkable pace.
McKinsey’s ‘The state of AI’ report shows 88% of organizations use AI in at least one business function, up from 78% last year; Gen AI adoption rose to 79% from 71%.
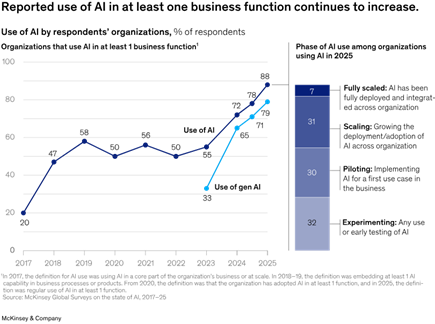
However, to make LLMs reliable, analysts such as Gartner predicts “by 2028, 50% of Organizations will adopt zero-trust data governance as unverified AI-generated data grows ”. This is why semantics, lineage, governance, and unified data estates have become inseparable from enterprise‑grade AI. The discussion has evolved from asking “Which model should we use?” to “How do we ensure our data is trustworthy, consistent, and comprehensible so models don’t hallucinate?”
As AI adoption matures from experimentation to enterprise scale:
- Modern enterprises are expanding investment on data governance to build trust.
- Enterprises need LLM-ready data catalogs with clear semantics, lineage, and tags.
- As RAG‑based AI and domain‑specific agents are evolving, enterprises require governance that ensures users and models only access authorized, trusted data.
Unity Catalog now sits at the center of this shift, emerging as the default governance layer within Databricks. Its AI‑native capabilities such as narrative generation and secure tool calling capabilities enable responsible democratization of data. Unity Catalog not only unifies data and AI governance within Databricks, but also complements existing enterprise metadata and governance platforms, enabling a federated governance model that balances enterprise oversight with platform‑level enforcement.
Solution and Recommendations: Building AI and LLM on a Solid Foundation
To develop AI or LLM-ready data foundations using Unity Catalog, I clarify both the "what" and "how" components of the solution, then outline best practices for ongoing improvement. The main goal is to form an AI‑ready semantic layer within Unity Catalog by supplying semantic context, specialized tags, indexing, and strong governance, making it easy to integrate with LLM and natural language applications.
1. What: Establish an AI‑Ready Semantic Foundation in Unity Catalog
The “what” focuses on the features within Unity Catalog that must be considered so that both users and AI agents can reliably understand and use enterprise data. The features that needs to be considered:
- Data tag such as Domain tags (Finance, Supply Chain, and HR etc.), Metric tags (KPIs, calculations and aggregations), Sensitivity tags (PII and confidential data) and Functional tags (Sales pipeline, inventory, and workforce) to improve searchability and relevance. These tags reduce noise, boost agent accuracy, and enable NLP to automatically query the right datasets. Metric view such as revenue, churn, stock coverage, Customer/Vendor OTIF, etc. to prevent formula hallucination. Since LLMs don’t invent formulas, they reuse these certified definitions.
- Vector Search Index that help LLMs retrieve tabular data, policies, SOPs, domain documentation, KPIs and business glossaries. This makes business-focused answers possible.
2. “How” to get started
- Begin by cataloging the most important datasets to demonstrate early success.
- If ETL pipelines are already in place but not yet connected to Unity Catalog, prioritize integrating them as the next step.
- Set granular access controls to protect data.
- Conduct data profiling within Unity Catalog to detect anomalies and outliers.
- Incorporate both technical and business data quality rules derived from profiling into the ETL pipeline.
- Use built-in auditing and lineage tools to maintain transparency and build trust with stakeholders and regulators.
- Train teams on intuitive search and governance features to increase adoption.
- Iterate and expand. Add data assets incrementally to maximize value and avoid overload.
3. Incorporate lessons learned as best practices such as
- Catalog Maintenance: Metadata management is not a one‑time activity; clear standards and guidelines will be established for data stewards to maintain definitions, tags, and lineage throughout the entire lifecycle of each data product.
- Data Quality: As AI and LLM use cases expand, data comes under greater scrutiny. Continuous monitoring of freshness, accuracy, integrity, and uniqueness becomes essential to ensure reliable outcomes and prevent garbage‑in, garbage‑out scenarios..
- Security: As data product usage expands, whether for AI/LLM workloads or for generating new derived data products, security requirements increase accordingly. Clear strategies and SOPs will be established to implement fine‑grained access controls and ensure responsible, compliant data access.
- Data Literacy: Training users on basic governance concepts becomes non‑negotiable.
Barriers and Success Stories
The primary challenge to successfully operationalizing Unity Catalog and AI‑ready data governance is not technology, but organizational mindset. Enterprise Data Management is often viewed as an additional task and consequently overlooked until critical issues arise. In addition, accountability remains another concern such as who manages tags, who oversees metric views, and who validates or endorses datasets?
Consider Unity Catalog as short‑term win and long-term strategy for context intelligence. It delivers immediate advantages like discoverability, tags, and lineage, while evolving into the core governance solution for AI workloads.
Conclusion
AI will only be as smart and insightful as the context we provide to it. For enterprises adopting AI, this is the time to invest in governance, metadata discipline, lineage, and domain clarity. Unity Catalog streamlines those principles into real operational foundations. It unifies data and AI governance going beyond being a simple metadata registry. With enriched metadata, business‑aligned tags, standardized metrics, vector indexes, and domain‑specific agents, enterprises can finally build LLM applications that are accurate, governed, and production‑ready.
References
• McKinsey’s The state of AI in 2025 report, 2025
https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
• Gartner’s prediction and approach to control unverified AI-Generated data ,2026
