Building a Robust Disaster Recovery Strategy for AWS IoT Core

IoT systems rarely fail quietly. When they fail, they do so at scale. As IoT adoption accelerates, millions of connected devices now depend on cloud platforms for continuous connectivity and data exchange. While cloud providers offer strong zone-level redundancy, regional outages remain a real and critical risk.
A full regional failure of a cloud provider can bring down device connectivity, halt data ingestion, and disrupt downstream business operations. The impact is not only financial but reputational. Recent incidents across major cloud providers like AWS and Azure have reinforced one reality: availability at scale requires deliberate disaster recovery design.
For mission-critical IoT deployments, AWS IoT Core disaster recovery is no longer optional. Therefore, organizations must engineer resilience into their platforms from day one rather than treating it as an afterthought.
Why Disaster Recovery Matters
A well-defined disaster recovery (DR) strategy ensures business continuity during unexpected failures. I always anchor DR planning around two non-negotiable metrics:
- Recovery Time Objective (RTO): The maximum acceptable downtime after a failure
- Recovery Point Objective (RPO): The maximum acceptable data loss the system can tolerate
These objectives should never be retrofitted. They must be defined early, during solution architecture and platform design.
In IoT ecosystems, two DR approaches are most commonly adopted:
- Pilot Light: A cost-effective model with minimal standby resources and longer recovery time
- Hot Site: A higher-cost approach offering near-immediate recovery and continuous availability
This blog focuses on implementing a Hot Site strategy for AWS IoT Core, covering four critical aspects:
1. Domain Name System (DNS)
2. Device Onboarding
3. Data Ingestion
4. Cross-Region Replication
The architecture diagram below illustrates a holistic view of Hot Site implementation for AWS IoT Core.
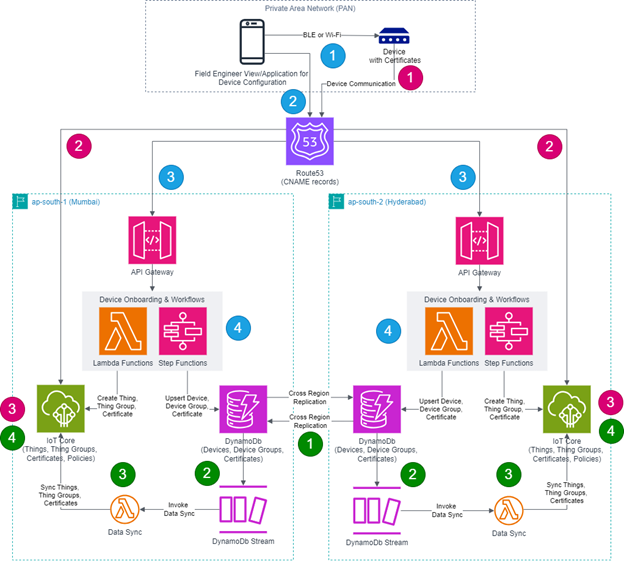
1. Domain Name System (DNS)
DNS sits at the heat of any effective disaster recovery strategy. AWS IoT Core endpoints use region-specific internal domains. Configuring these endpoints directly on devices tightly couples them to a single region and complicates recovery.
To avoid this, I rely on AWS Route 53 as the abstraction layer.
The approach includes
- Creating a custom domain with a public hosted zone
- Defining DNS records for API and IoT endpoints, primarily using CNAME records
- Registering IoT endpoints across multiple AWS regions to ensure seamless device functionality
- Configuring devices to use the custom DNS record rather than regional endpoints
This abstraction allows seamless redirection during failures.
For Pilot Light scenarios, DNS failover can be enabled by:
- Creating DNS records with CNAME entries for API and IoT endpoints
- Configuring health checks to detect failures and trigger failovers
DNS-based routing ensures devices reconnect without requiring firmware changes or manual intervention.
2. Device Onboarding
Secure device enrollment is typically managed through an IoT application for security reasons. In the architecture diagram, this role is represented by mobile application.
The mobile application must have all the logic required for device onboarding, including:
- Communicating with the device interface using PAN protocols via Bluetooth Low Energy (BLE) or Wi-Fi and gathers device information.
- Calling API endpoint to register IoT device with platform and getting device certificates.
Storing certificates into device securely again via PAN protocol.
- The API endpoint resolves via DNS to one of several regional API Gateway endpoints
- The backend workflow creates Things, Thing Groups, and Certificates in AWS IoT Core
- Device metadata and certificates (public, private and CA) are stored in DynamoDB for cross-region replication.
In some cases, firmware updates are also delivered through the mobile application. Devices typically include logic to handle secure updates.
Most consumers have already interacted with similar systems. Home appliances, such as smart air conditioners, follow this exact onboarding pattern using companion mobile apps to be downloaded from Google Play Store or Apple Store for consumers, like us, to aboard their product onto the provider’s IoT platform.
3. Data Ingestion
Once onboarded, devices must reliably ingest telemetry into the platform. The ingestion flow includes:
- Configuring devices with IoT endpoint, certificates, and other metadata using mobile app or it can be pre-configured.
- IoT device initiates secure connection to configured IoT endpoint for ingesting data into the IoT Core .
- Resolving one of the CNAME records of IoT Core endpoints from different regions .
- IoT Core authenticates the device identity using device certificate.
This design ensures devices can connect transparently to the active region during both steady-state operations and failover scenarios, a foundational requirement for effective disaster recovery for IoT platforms.
4. Cross-Region Replication
While AWS IoT Core maintains its own device registry, I rely on DynamoDB as the foundation for enabling reliable cross-region recovery. It serves as the system of record for device metadata and certificates, making it critical to any multi-region disaster recovery design.
Key design considerations include:
- DynamoDB Streams enable event-driven synchronization workflows. Whenever a new record is added to the DynamoDB table, an event is generated in DynamoDB Streams. This event triggers a Lambda function or workflow that contains the logic to identify cross-region records and synchronize them by creating the required Things, Thing Groups, and Certificates within the AWS IoT Core service in the target region.
- Idempotency must be enforced in all data synchronization logic to prevent duplicate processing. Cross-region replication workflows must be designed to handle repeated or replayed events gracefully, ensuring that duplicate records do not result in inconsistent state or failed provisioning operations.
- In the recovery region, AWS IoT Core must be populated with Things, Thing Groups, and Certificates derived from replicated DynamoDB records . Once these elements are present in the recovery region, IoT Core can successfully validate incoming IoT device connection requests without requiring re-enrollment or manual intervention.
- Telemetry data must also be replicated across regions to ensure availability. This typically requires dedicated storage layers for both hot and cold telemetry data. These storage systems should support near real-time replication to the recovery region. The architecture diagram does not depict telemetry storage, which is often implemented as time-series data storage, but it remains a critical component of a complete disaster recovery strategy.
Infrastructure As Code (IaC)
Disaster recovery depends on speed and repeatability. Infrastructure as Code makes both possible.
With IaC scripts in place, infrastructure can be provisioned rapidly in a recovery region during an incident. This approach is often paired with Pilot Light strategies but benefits Hot Site deployments as well.
Common tools include:
- Terraform
- AWS CloudFormation
- AWS CDK
Automation eliminates manual errors and ensures consistency during high-pressure recovery scenarios.
Best Practices for AWS IoT Core Disaster Recovery
Based on experience, I recommend the following practices:
- Define RTO and RPO early in the design phase
- Use Route53 health checks for automated DNS failover
- Leverage DynamoDB global tables for metadata and certificate replication across regions
- Implement idempotent workflows for cross-region data synchronization
- Maintain IaC scripts for rapid environment setup
- Never configure IoT device with AWS-provided IoT Core endpoints
- Never configure mobile app with AWS-provided API Gateway endpoints
- Regularly test failover scenarios to validate recovery objectives
Conclusion
Disaster recovery for IoT is not about preparing for rare events. It is about designing for inevitability. Regional outages will happen. The question is whether systems are prepared to recover gracefully.
By combining AWS IoT Core with Route 53, DynamoDB, and supporting services, organizations can build IoT platforms that remain resilient under pressure. More importantly, they can protect customer trust, operational continuity, and long-term business value.
As IoT ecosystems continue to scale, resilience must evolve from an architectural feature into a core design principle. The platforms that succeed will be the ones designed not just to connect devices, but to endure disruption.
