Under the Hood on Techniques Used by DeepSeek–A Deep Dive!
Feb 12, 2025

Introduction to DeepSeek
As AI advances, businesses are constantly exploring new ways to harness its power. Staying ahead in this landscape means embracing Enterprise AI trends that prioritize both creativity and complex reasoning tasks. DeepSeek marks a groundbreaking advancement in the field of large language models (LLMs), particularly in their ability to perform complex reasoning tasks. Unlike traditional chat models, which excel at generating creative content and handling customer service inquiries, reasoning models like DeepSeek have a different focus. They are designed to tackle more intricate tasks such as financial analysis, scientific research, and complex inferences. The first-generation models, DeepSeek-R1-Zero and DeepSeek-R1, have already set new benchmarks in the industry. Both these models are built on the robust DeepSeekV3 base model.Under the hood
Salient features of the foundation model DeepSeekV3
The DeepSeekV3 base model incorporates unique features such as Multi-Token Prediction (MTP), FP8 mixed precision training, and the DeepSeekMoE (Mixture of Experts) architecture. These features collectively enhance model performance, reduce memory requirements, and accelerate inference.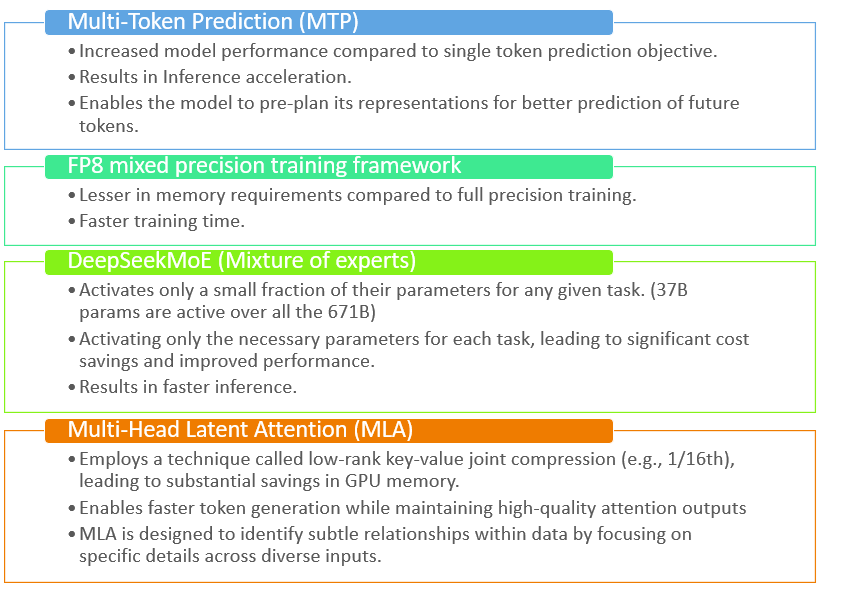
Fig 1: Features of DeepSeek V3
The unique combination of above features in DeepSeekV3 accounts for speed, cost-effectiveness, and scalability.Methods employed to develop DeepSeek-R1
1.0.1.1 Training process and efficiency DeepSeek employs a distinct and highly efficient, four-step training process. The process is designed to ensure the model's reasoning capabilities through a rule-based reinforcement learning while maintaining general capabilities with comprehensive fine-tuning data. A key component of this process is Group Relative Policy Optimization (GRPO), which evaluates groups of responses relative to one another. By eliminating the need for an additional critic model, GRPO improves reasoning precision while enhancing overall training efficiency.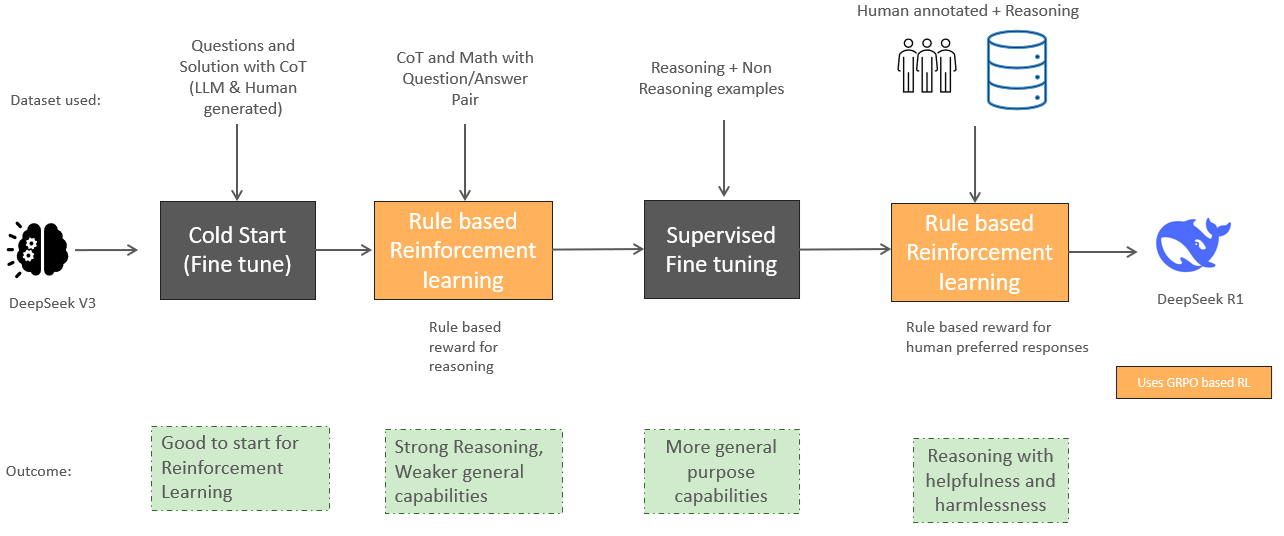
Figure 2: Four Step Training Process
Step 1: Cold-start data refers to a small amount of high-quality, supervised data used to initialize or “kickstart” the training of a machine learning model, particularly in scenarios where the model is being trained from scratch or transitioning to a new task. Step 2: Apply GRPO to the fine-tuned model, focusing on reasoning-intensive tasks (e.g., math, coding, logic). A language consistency reward is introduced to reduce language mixing and improve readability.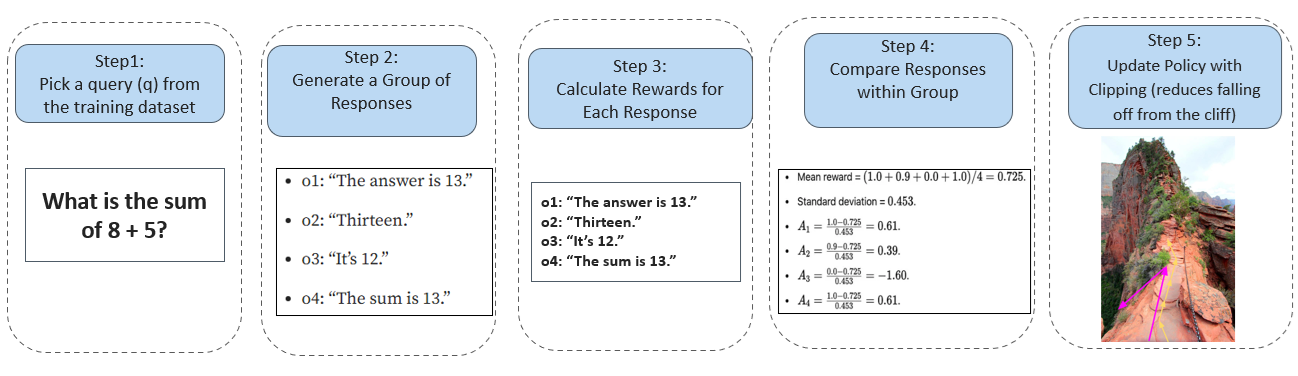
Figure 3: GRPO Essentials
Reference : https://huggingface.co/blog/deep-rl-ppo Step 3: After RL converges, collect high-quality reasoning and non-reasoning data (e.g., writing, role-playing) through rejection sampling and fine-tune the model for general-purpose tasks using this high-quality data. Step 4: Perform a second RL stage to align the model with human preferences, improving helpfulness and harmlessness while maintaining strong reasoning capabilities. 1.0.1.2 Model distillation and deployment One of the standouts feature of DeepSeek is its ability to distil its outputs into smaller, more efficient reasoning models. This distillation process ensures that these models can be deployed on commodity hardware, making advanced reasoning capabilities more accessible and cost-effective. Notably, these models outperform non-reasoning counterparts like GPT-4o-0513 across a variety of tasks. 1.0.1.3 Performance and cost efficiency DeepSeek-R1's training and inference processes are designed to be faster and more cost-effective compared to other models. For instance, the training cost of DeepSeek-R1 is significantly lower than that of OpenAI's o1 series, with a total cost of US$ 6 million compared to US$ 6 billion for OpenAI's model. Additionally, DeepSeek-R1 uses fewer GPU hours, making it a more resource-efficient option. This combination of lower costs and faster processing makes DeepSeek-R1 an attractive option for businesses exploring Enterprise AI trends to integrate high-performance systems. Below is a summarized view of why DeepSeek-R1 training and inference is faster with performance gain: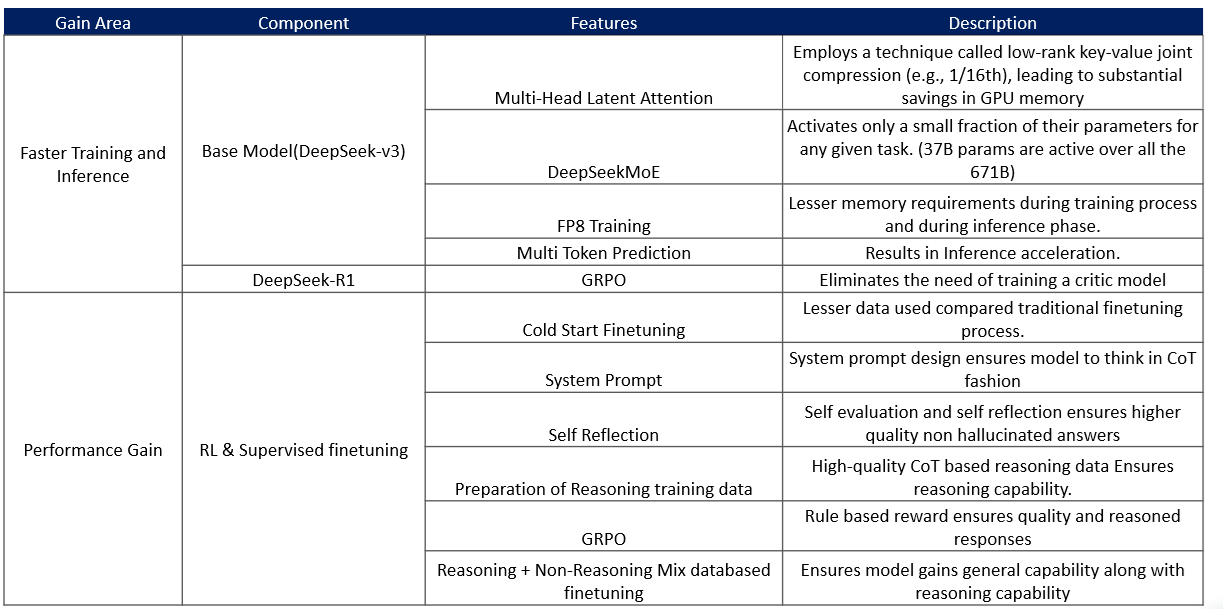
Figure 4: DeepSeek R1 Processes
