Beyond Data: Building Trust for Effective AI and Decision-Making
Oct 31, 2025

Trust cannot exist as a one-time project or a neatly contained initiative. It’s the continuously evolving foundation of intelligent enterprise. It must be engineered into data systems, reinforced by governance, and reflected in every AI-assisted decision. Though invisible, trust anchors everything, turning information into insight and technology into impact.
In this AI-first era, the strength of every decision depends on the trusted data foundation powering it. Enterprises understand that AI can transform how they operate, yet many projects stall before delivering impact. The real barrier is rarely the algorithm; it’s the absence of trust. When data is incomplete, inconsistent, or biased, everything built on it begins to falter. Even the most advanced AI models reflect that uncertainty, producing outcomes that feel slightly off, sometimes dangerously so.
For AI to move from promise to practice, trust must be engineered into every layer of the data lifecycle: from collection to governance and security to decision-making. Building that trust is about accountability, discipline, and continuous evolution. Treating data as a living product rather than a static asset.
This blog explores what it takes to build, sustain, and scale trust: why it erodes and how a resilient, trust-first culture can become a defining trait of modern enterprises.
 The first dimension is where you need all your enterprise data to be robust. Data quality, data lineage, metadata framework, and data governance framework should be in place for conventional data, and that governs all enterprise data.
The second dimension has unstructured and streaming data. Consider enterprise emails, enterprise SharePoint or contact center call recordings for example. All those elements would become unstructured data, which would augment the existing enterprise data, so you need to have a bit more sophisticated mechanism for governing that.
Agents constitute the third dimension. So, how do you govern agent behavior? A robust agent governance framework is very important to analyze how agents are functioning.
Tools must be available for each of those areas right from the start. Things may go wrong from acquisition to distribution, even in the APIs that you have. This is an interesting area that will keep evolving.
The first dimension is where you need all your enterprise data to be robust. Data quality, data lineage, metadata framework, and data governance framework should be in place for conventional data, and that governs all enterprise data.
The second dimension has unstructured and streaming data. Consider enterprise emails, enterprise SharePoint or contact center call recordings for example. All those elements would become unstructured data, which would augment the existing enterprise data, so you need to have a bit more sophisticated mechanism for governing that.
Agents constitute the third dimension. So, how do you govern agent behavior? A robust agent governance framework is very important to analyze how agents are functioning.
Tools must be available for each of those areas right from the start. Things may go wrong from acquisition to distribution, even in the APIs that you have. This is an interesting area that will keep evolving.
 Successfully navigating these expectations requires a holistic governance framework that addresses all four pillars of trust. It is not enough to secure data if it is not accessible, nor is it valuable to make data accessible if it is not dependable.
Successfully navigating these expectations requires a holistic governance framework that addresses all four pillars of trust. It is not enough to secure data if it is not accessible, nor is it valuable to make data accessible if it is not dependable.
The Data Lifecycle: A Chain of Trust
Let’s decode a chain of trust across the data lifecycle. From its initial acquisition to its eventual retirement, data passes through multiple stages, each presenting unique opportunities (or challenges) for its integrity to be compromised.- Data Acquisition and Ingestion: This is the gateway where data enters your systems. Whether it’s transactional data, streaming data, or confidential data, without robust checks and balances, incomplete or inaccurate data can hamper training models, affect the next action, and easily pollute the entire ecosystem. A scalable and well-designed data fabric enables seamless ingestion from multiple sources while maintaining strong security controls. By integrating large language models (LLMs) with enterprise data through retrieval-augmented generation (RAG) or specialized language models (SLMs), organizations can build expert systems that drive informed decision-making. However, this foundation must be protected from bias and poor governance. Compromised or “hallucinated” data can distort AI outputs, weaken trust, and create downstream risks that undermine the integrity of enterprise intelligence.
- Transformation and Governance: Once acquired, data is transformed, cleaned, and governed. This phase involves applying rules for data management, establishing metadata frameworks, and ensuring quality. However, I’ve also seen a lot of data duplication or inconsistent records in this phase, which can run rampant. An organization might believe it has a single "golden record" for a customer, only to find multiple, conflicting versions scattered across different systems. Training an AI model on such fragmented data is a recipe for failure, as the model’s predictions will be based on an inconsistent and inaccurate view of reality. Robust data governance for AI, spanning lineage, quality controls, and policy enforcement, prevents these inconsistencies from cascading into models and decisions
- Consumption and Decision-Making: This is where the value of data is realized. From business analysts to AI models, downstream stakeholders consume this data to generate insights and drive decisions. These users inherently trust that the information presented to them is accurate. If a sales dashboard reflects data that is four days old because of complex data pipelines, a CEO loses confidence not just in the report, but in the entire data infrastructure and AI initiative. With dependable, current inputs, teams can trust AI-powered decision-making instead of second-guessing stale dashboards.
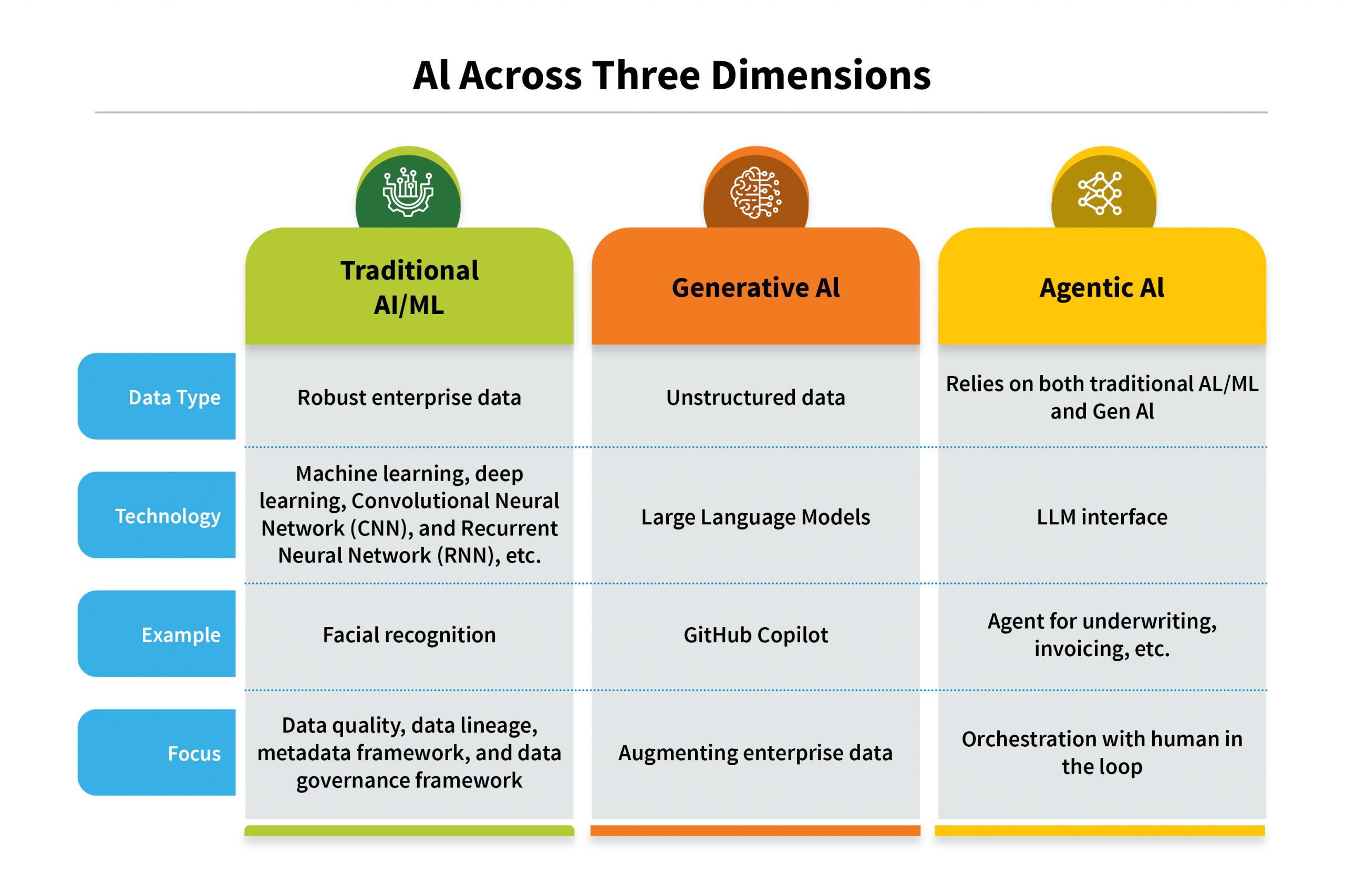
AI Across Three Dimensions
Across all three dimensions of AI, trust in the data lifecycle is the common thread that determines success. Whether it’s ensuring the accuracy of training data for traditional AI, preventing hallucinations in generative AI, or enabling ethical decision-making in agentic AI, trust must be engineered into every stage of the lifecycle. Without it, the potential of AI to transform enterprises is compromised, leading to unreliable outcomes and eroded confidence. Here’s a quick overview of data across all three dimensions: Traditional AL/ML, Generative AI, and Agentic AI.
The first dimension is where you need all your enterprise data to be robust. Data quality, data lineage, metadata framework, and data governance framework should be in place for conventional data, and that governs all enterprise data.
The second dimension has unstructured and streaming data. Consider enterprise emails, enterprise SharePoint or contact center call recordings for example. All those elements would become unstructured data, which would augment the existing enterprise data, so you need to have a bit more sophisticated mechanism for governing that.
Agents constitute the third dimension. So, how do you govern agent behavior? A robust agent governance framework is very important to analyze how agents are functioning.
Tools must be available for each of those areas right from the start. Things may go wrong from acquisition to distribution, even in the APIs that you have. This is an interesting area that will keep evolving.
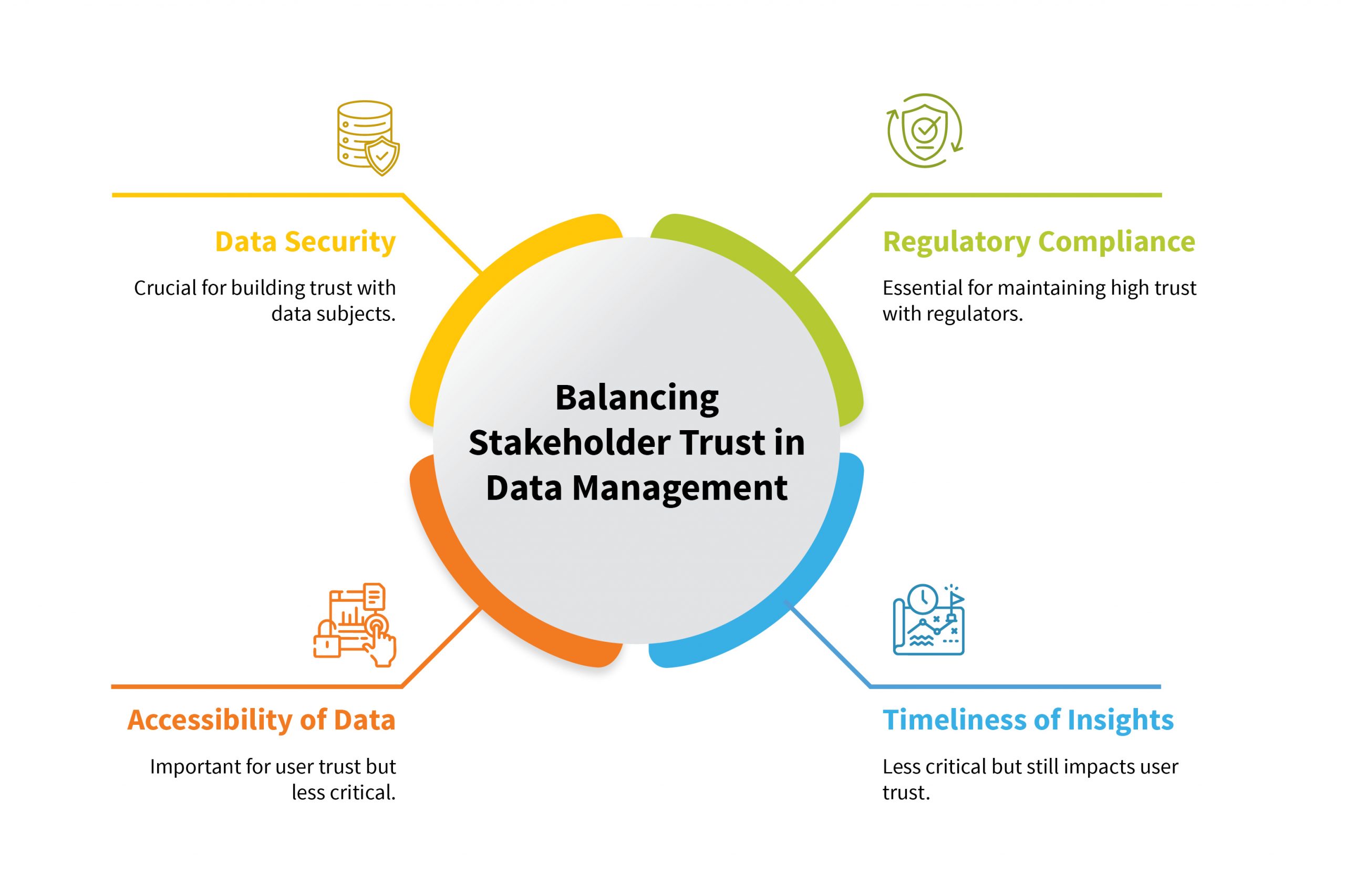
The Pillars of a Trustworthy Data Foundation
To counteract the risks of trust erosion, enterprises must build their data strategy on four fundamental pillars. These principles provide a framework for measuring and enforcing trust across the organization.- Dependability
- Transparency
- Accountability
- Accessibility
Successfully navigating these expectations requires a holistic governance framework that addresses all four pillars of trust. It is not enough to secure data if it is not accessible, nor is it valuable to make data accessible if it is not dependable.
